This tutorial explores how to scrape sites where the content is loaded dynamically via JavaScript. The tools we use are Python, PhantomJS and Selenium. You can clone the github repository from here.
Problem
Nowadays a lots of sites use JavaScript to load their content dynamically. For example let’s take a look at ATP Singles USA tennis results 2015. You can see that all the matches are listed below:
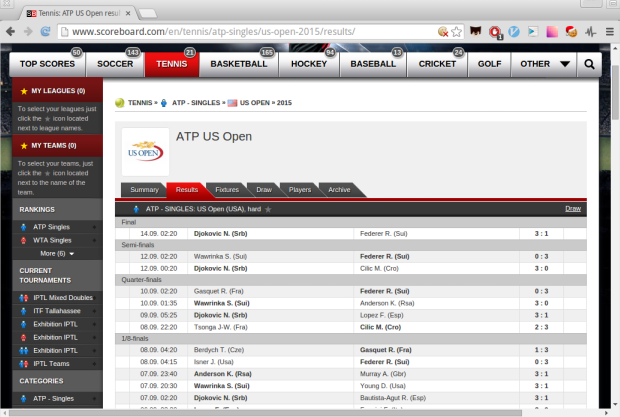
but if we disable JavaScript the page keeps loading infinitely:
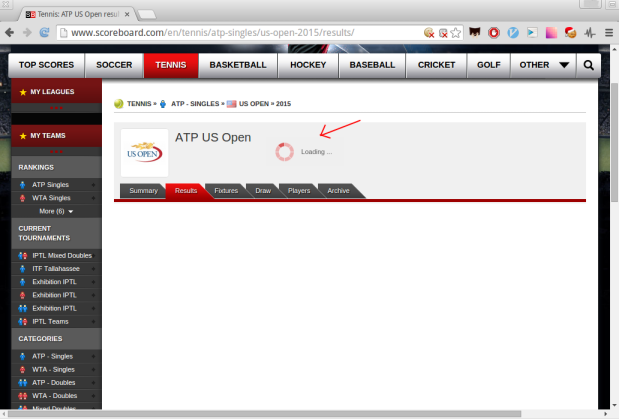
What if we want to get all the games from that site using Python? Surely the classic way of just sending the request to the site and parsing the html won’t work as JavaScript is not rendered and thus the body of the page is incomplete.
PhantomJS and Selenium to the Rescue
First we’ll set up our environment:
techstonia:~$ mkdir scraping_phantomjs && cd scraping_phantomjs
techstonia:~$ virtualenv venv
techstonia:~$ source venv/bin/activate
(venv)techstonia:~$ pip install selenium beautifulsoup4Let’s make python file named scraper.py
(venv)techstonia:~$ touch scraper.pyand fill it up with our script:
import platform
from bs4 import BeautifulSoup
from selenium import webdriver
# PhantomJS files have different extensions
# under different operating systems
if platform.system() == 'Windows':
PHANTOMJS_PATH = './phantomjs.exe'
else:
PHANTOMJS_PATH = './phantomjs'
# here we'll use pseudo browser PhantomJS,
# but browser can be replaced with browser = webdriver.FireFox(),
# which is good for debugging.
browser = webdriver.PhantomJS(PHANTOMJS_PATH)
browser.get('http://www.scoreboard.com/en/tennis/atp-singles/us-open-2015/results/')
# let's parse our html
soup = BeautifulSoup(browser.page_source, "html.parser")
# get all the games
games = soup.find_all('tr', {'class': 'stage-finished'})
# and print out the html for first game
print(games[0].prettify())NB! In order for this script to work we must specify where to find PhantomJS. The phantomjs file can be found from here. Just download the correct version according to your operating system. Then unpack it and the file named ‘phantomjs’ can be found under the bin folder. Copy the file into the same folder as the scraper.py script.
Now lets run our script:
(venv)techstonia:~$ python scraper.py and we get the html for the first match, which happened between Djokovic and Federer:
<tr class="odd no-border-bottom stage-finished" id="g_2_2DtOK9O8">
<td class="cell_ib icons left ">
</td>
<td class="cell_ad time ">
14.09. 02:20
</td>
<td class="cell_ab team-home bold ">
<span class="padl">
Djokovic N. (Srb)
</span>
</td>
<td class="cell_ac team-away ">
<span class="padl">
Federer R. (Sui)
</span>
</td>
<td class="cell_sa score bold ">
3 : 1
</td>
<td class="cell_ia icons ">
<span class="icons">
</span>
</td>
</tr>Summary
As we saw it’s relatively easy to get dynamically loaded content, although it’s a bit slower than the traditional method of just firing a request to the server. You can clone the github repository from here.